Holy cow! Can you believe your luck? What better way to spend some portion of whatever day of the week it is than to think about parallelizing reduction algorithms?
Really? You can't think of one? In that case, I'll kick off our inevitable friendship by contributing a clojure
implementation of a fancy algorithm that asynchronously reduces arbitrary input streams while
preserving order. Then I'll scare you with glimpses of my obsessive quest to visualize what this
algorithm is actually doing; if you hang around, I'll show you what I eventually cobbled together
with clojurescript and reagent. (Hint. It's an ANIMATION! And COLORFUL!)
(If you want to play with the algorithm or the visualization yourself, it's better to clone it from github than to attempt copying and pasting the chopped up code below.)
Every hand's a winner
The first really interesting topic in functional programming is reduction. After absorbing the idea that mutating state is a "bad thing", you learn that you can have your stateless cake and eat it too.
(reduce + 0 (range 10))
does essentially the same thing as
int total=0;
for (int i=0; i<10; i++) {
total += i;
}
return total;
without the fuss of maintaining the running sum explicitly. It becomes second nature to translate this sort
of accumulation operation into a fold, and it's usually foldl - the one where the running accumulant is
always the left-hand side of the reduction operator.
foldl and foldr considered slightly harmful
In August 2009, Guy Steele, then at Sun Microsystems, gave a fantastic talk titled Organizing Functional Code for Parallel Execution; or, foldl and foldr Considered Slightly Harmful, alleging that this beautiful paradigm is hostile to concurrency. He's right. By construction, you can only do one reduction operation at a time. That has the advantage of being extremely easy to visualize. ASCII art will do (for now):
1 a b c d e f g h
\ / / / / / / /
2 ab / / / / / /
\ / / / / / /
3 abc / / / / /
\ / / / / /
4 abcd / / / /
\ / / / /
5 abcde / / /
\ / / /
6 abdef / /
\ / /
7 abcdefg /
\ /
8 abcdefgh
Here, we are concatenating the first 8 letters of the alphabet, and it will take us 7 sequential steps (aka O(n)) to do it.
Steele points out that you can do better if you know in advance that your reduction operator is associative; we can do bits of
the reduction in parallel and then reduce the reduced bits. Concatenation is the ultimate in associative operators; we can grab
any random consecutive sequence and reduce it, then treat the reduction as if it were just another element of input, e.g.
a b c d e f g h --> a b c def g h --> abc def gh --> abcdefgh
Approaching this not so randomly, we can repeatedly divide and conquer
1 a b c d e f g h
\ / \ / \ / \ /
2 ab cd ef gh
\ / \ /
3 abcd efgh
\ /
4 abcdefgh
now completing in only takes 3 steps (aka O(log n)).
The main thrust of Steele's talk is that you should
use data structures that foster this sort of associative reduction. The minimal requirement of
such a structure is that you're in possession of all its elements, so you know how to divide
them in half.
This may remind you of merge-sort, which is in fact a parallelizable, associative reduction, taking advantage
of the fact that merging is associative.
associative vs commutative
Suppose, however, that you're reducing a stream of unknown length. It isn't clear anymore how to divvy up the inputs. That isn't a problem if our reduction operation is commutative, rather than just associative. In that case, we can just launch as many reductions as we can, combining new elements as they become available with reduced values, as they complete. If the reduction operator isn't actually commutative, accuracy will suffer:
1 a b c d e f g h
\ / \ / / | | |
2 ab \ / / | | |
\ cd / | | |
\ \ / | | |
\ /\ / | |
\ / \ / | |
3 abe \ / / |
\ cdf / |
\ \/ |
\ /\ /
4 abeg cdfh
\ /
5 abegcdfh
To take an extremely practical example, suppose I needed to keep track of the orientation of my remote-control spaceship (USS Podsnap), which transmits to me stream of 3D rotation matrices, each representing a course correction. Matrix multiplication is associative, so a streaming associative reduce is just the ticket. Matrix multiplication is not, however, commutative, so if I mess up the order I will be lost in space. (Note that 2D rotation matrices - rotation around a single angle - are commutative, so this wouldn't be a problem for my remote-control wheat combine.)
It seems that I truly need a true streaming, associative reduce -- where order matters, but nobody has told me when inputs will stop arriving, at what rate they will arrive, or how long the reductions themselves will take.
streaming associative reduce - a possible algorithm
Here's a possible approach. We maintain multiple queues, and label them 1, 2, 4 etc., corresponding to reductions of that many elements. When the very first element arrives, we throw it onto (the empty) queue #1. When subsequent elements arrive, we check if there's anything at the head of queue #1 and, if so, launch a reduction with it; otherwise, we put it in queue #1. If we do launch a reduction involving an element from queue #1, we'll add a placeholder to queue #2, into which the result of the reduction will be placed when it completes. After a while queue #2 may contain a number of placeholders, some populated with results of completed reductions, others still pending. As soon as we have two complete reductions at the head of queue #2, we launch a reduction for them, and put onto queue #4 a placeholder for the result. And so on.
Sometime after the stream finally completes, we'll find ourselves with all queues containing zero or one reduced value. Because of the way we constructed these queues, we know that any reduction in queue i involves only inputs elements preceding those involved in reductions in any other queue j<i. Accordingly, we just take the single values remaining, put them in reverse order of bucket label, and treat them as a new input series to reduce.
I think we're almost at the limits of ASCII visualization, but let's try anyway. Values in parentheses below are pending:
1 2 4
---------- ----------- -------
a
a b
c (ab)
c d ab
e ab (cd)
e f ab cd
g (ef) (abcd)
g h ef abcd
ef (gh) abcd
efgh abcd
abcd efgh
(abcdefgh)
abcdefgh
The actual state at any point in time, is going to depend on
- When inputs arrive.
- The amount of time a reduction takes.
- The permitted level of concurrency.
Note that you might not actually achieve the permitted level of concurrency, because we don't yet have two consecutive reductions at the front of a queue. Suppose that queue 2 looks like this (left is front):
2: (ab) cd (ef) gh
For some reason reducing a/b and e/f is taking longer than reducing c/d and g/h. Only when a/b finishes
2: ab cd (ef) gh
can we grab the two head elements and launch a reduction of them in queue #4
2: (ef) gh
4: (abcd)
Now imagine a case where reductions take essentially no time compared to the
arrival interval. Since we do a new reduction instantly upon receiving a new
element, the algorithm reduces to foldl, plus a decorative binary counter
as we shuffle partial reductions among the queues:

Now another, where inputs arrive as fast as we take them,
reductions take 1 second, and we can do up to 10 of them at a time.
(n is the actual number of inputs left;
np is the actual number of reductions currently running; green
squares represent the number completed reductions, red the number in flight
;the actual ordering of reductions and placeholders in the queue is not shown):
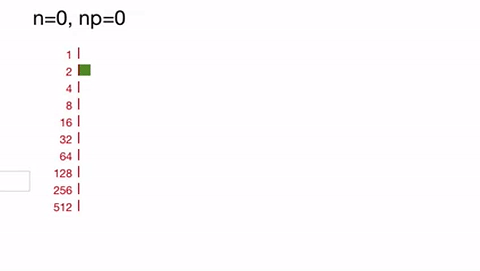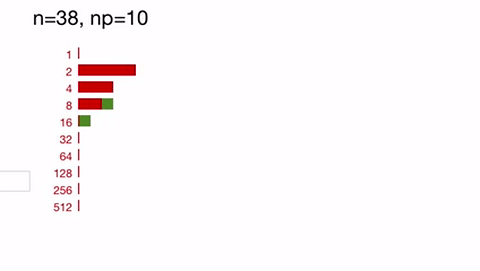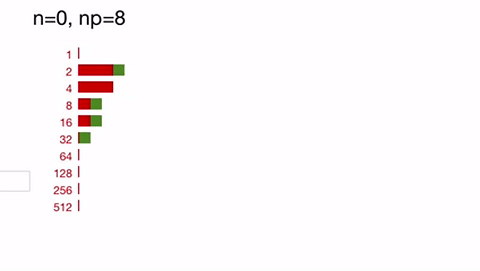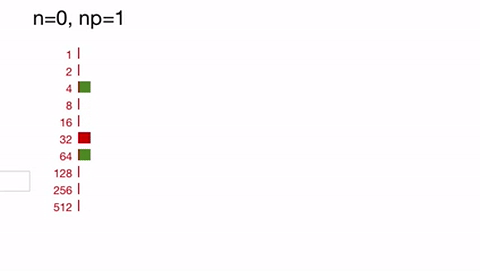
See how we immediately fill up queue #2 with placeholders for 10 reductions, which we replenish as they complete and spill over into later buckets.
Finally, here's a complicated example: inputs arrive every millisecond (essentially as fast as we can consume them), reductions take between 1 and 100ms, and we are willing to run up to 10 of them in parallel.

It achieves pretty good concurrency, slowing down only during the final cleanup.
Learn to play it right
Clojure of course contains reduce (and educe and transduce and... well, we've
been
down
that
road
already), and it even
contains an associative reduce, which sticks it to those stuck-up
Haskellers by calling itself fold.1
Our reduce will look like
(defn assoc-reduce [f c-in])
where f is a function of two arguments, returning a core.async channel that delivers their reduction and c-in is a channel
of inputs; assoc-reduce returns a channel that will deliver the final reduction. In typesprach it
would look like this:
(defn :forall [A] assoc-reduce
([f :- (Fn [A A -> (Chan A)])
c-in :- (Chan A)
] :- (Chan A)))
The central data structure for this algorithm is a queue of place-holders, which I ultimately implemented as a vector of volatiles. That's a bit of a compromise, as it would be possible to employ a fully functional data structure, but we can structure our code to localize the impurity.
When launching a reduction, we place new
(volatile! nil) at the
end of the queue where its result is supposed to go, and when the answer comes back,
we reset! the volatile. Crucially, we do not let this resetting occur
asynchronously, because we're going to want to identify all pairs of completed reductions later,
and it would be disruptive for results to teleport in while we're inspecting. Instead,
we'll arrange for each incoming reduction results to be accompanied by the destination volatile,
in which we can choose to place it at a time of our choosing.
(let [iq (inc old-queue-number)
v (volatile! nil)
queues (update-in queues [iq] conj v)] ;; put placeholder volatile on queue
(go (>! reduction-channel ;; launch reduction asynchronously
[iq ;; queue number
(<! (f a b) ;; reduction resut
v]]))) ;; destination volatile
The main loop now knows exactly where to put the results, and we know exactly when they were put there. No race conditions here.
(go-loop [queues {}]
(let [[iq r v] (<! reduction-channel)
_ (reset! v r)
queues (launch-reductions-using-latest queues)]
(recur queues)))
What then? After a reduction comes back, we may have an opportunity to launch more, by pulling pairs of reduced values off the the current queue (this is the operation we didn't want to be disrupted by incoming results) for further reduction into the next queue:
(defn launch-reductions [c-redn f iq queue]
(let [pairs (take-while (fn [[a b]] (and a b))
(partition 2 (map deref queue)))]
(map (fn [[a b]]
(let [v (volatile! nil)]
(go (>! c-redn [(inc iq) (<! (f a b)) v]))
v)) pairs)))
So far, we've thought about what to do with results coming off a reduction channel;
we also have to worry about raw inputs. Life will be a little simpler if we make
the input channel look like the reduction channel, so we map our stream of xs into
[0 x nil]s. One used to do this with (async/map> c-in f), but that's been deprecated
in favor of channels with built-in transducers, so we'll create one of those and pipe
our input channel to it:
(let [c-in (pipe c-in-orig (chan 1 (map (fn [x] [0 x nil]))))] ...)
Then we'll listen with alts! on [c-redn c-in], taking real or fake reductions
as they arrive.
Actually, it's a little more complicated than that, because we don't want to find
ourselves listening when no results are expected, and we don't want to accept more
inputs when already at maximum parallelization. This means we're going to have to
keep track of a little more state than just the queues. Specifically, we'll keep
c-in, with the convention that its set to nil when closed and np, the total
number of reductions launched:
(go-loop [{:keys [c-in queues np] :as state} {:c-in c-in :queues {} :np 0}]
The first thing we do in the loop is build a list of channels (possibly empty - a case we'll handle a bit further down)
(if-let [cs (seq (filter identity (list
(if (pos? np) c-redn) ;; include reductions if some are expected
(if (< np np-max) c-in) ;; include c-in if still open np<np-max
)))]
and listen for our "stuff":
(let [[[l res v] c] (alts! cs)]
The only reason we might get back nil here is that the input channel has been closed,
in which case we record that fact and continue looping:
(if-not l
(recur (assoc state :c-in nil))
If we do get back a reduction, we put it in the volatile expecting it,
(let [q (if v
(do (vreset! v res) (queues l)) ;; real reduction
(concat (queues 0) [(volatile! res)])) ;; actually an input
launch as many reductions as we can from pairs at the head of the queue,
vs (launch-reductions c-redn f l q)
nr (count vs)
q (drop (* 2 nr) q)
adjust the number of running reductions accordingly (if l is zero, this is an input,
which does not indicate that a reduction has finished),
np (cond-> (+ np nr) (pos? l) dec)
put the placeholders on the next queue,
l2 (inc l)
q2 (concat (queues l2) vs)]
and continue looping
(recur (assoc state :n n :np np :queues (assoc queues l q l2 q2))))))
In the case where c-in was closed and np was zero, our queues contain nothing but
complete reductions, which we extract in reverse order
(let [reds (->> (seq queues)
(sort-by first) ;; sort by queue number
(map second) ;; extract queues
(map first) ;; take the head, if any
(filter identity) ;; ignore empty heads
(map deref) ;; unpack the volatile
reverse
)]
If there's only one reduction, we're well and truly done. Otherwise, we treat the new series as inputs:
(if (<= (count reds) 1)
(>! c-result (first reds)) ;; return result
(let [c-in (chan 1 (map (fn [x] [0 x nil])))]
(onto-chan c-in reds)
(recur {:n (count reds) :c-in c-in :queues {} :np 0}))))))
Knowin' what the cards were
Surprisingly, it wasn't that difficult to get this working. While the state is a bit messy, we're careful to "modify" it only on one thread, and we enjoy the masochistic frisson of admonishment every time we type one of Clojure's mutation alert2 exclamation points.
Unfortunately, I suffer from a rare disorder in which new algorithms induce psychotic hallucinations. For hours after "discovering" binary trees as an adolescent, I paced slowly back and forth in my friend Steve's family's living room, grinning at phantom nixie numbers3 dancing before my eyes and gesticulating decisively, like some demented conductor. (Subsequently, I used that knowledge to implement in BASIC an animal guessing game, which I taught to disambiguate some kid named Jeremy from a pig with the question, "is it greasy?", so in some ways I was a normal teenager.)
The streaming reduce is particularly attractive - pearls swept forth in quadrilles and copulae - but I guess the graphic equalizer thingie is an ok approximation. Still, I couldn't even see how to make one of those without some horrible sacrifice, like learning javascript. Someday, I will be able to write only clojure, and some kind soul will translate it into whatever craziness the browser wants.
Someday is today
The combination of clojurescript and
reagent over react
allows you to do a tremendous amount with the bare minimum of webbish
cant. The basic idea of reagent is that you use a special
implementation of atom
(defonce mystate (r/atom "Yowsa!"))
which can be swap!ed and reset! as usual and, when dereferenced in the middle of HTML
(here represented as hiccup)
[:div "The value of mystate is " @mystate]
just plugs in the value as if it had been typed there, updating it whenever it changes. You can also update attributes, which is particularly interesting in SVG elements:
[:svg [:rect :height 10 :width @applause-volume]]
It's handy to use
core.async to glue an otherwise web-agnostic application to depiction in terms of r/atoms, e.g.
(go-loop []
(reset! mystate (use-contents-of (<! mychannel)))
(recur))
Since assoc-reduce was already keeping track of a state, I just
introduced an optional debug parameter - a channel which, if not
nil, should receive the state whenever it's updated. To simulate
varying rates of input and reduction, we use timeouts, optionally
fixed or random:
(defn pluss [t do-rand]
(fn [a b] (go (<! (timeout (if do-rand (rand-int t) t))) (+ a b))))
(defn delay-spool [as t do-rand]
(let [c (chan)]
(go-loop [[a & as] as]
(if a (do (>! c a)
(<! (timeout (if do-rand (rand-int t) t)))
(recur as))
(async/close! c)))
c))
There's some uninteresting massaging of the state into queue lengths, and some even less interesting boilerplate to read parameters from constructs originally intended for CGI, but in less than half an hour, the following emerges:
It would be more work to make this efficient and to prevent you from breaking it with silly inputs, but I feel vindicated in waiting for the clojurescript ecosystem to catch up to my laziness.
(Of course what I'm really hoping for is that somebody actually animates the dancing pearls for me. Or at least to tell me how to get a carriage return after the damn thing.)
Go forth and reduce!
-
Haskellers responds with wounding jeers that we do not understand monoids and semigroups, which we will pretend not to care about but obsess over in private. ↩
-
A trademark of Cognitect Industries, all rights reserved. ↩
-
Yes, numbers. We didn't have pointers back then, so you made structures with arrays of indices into other arrays. Glory days. ↩
Comments
comments powered by Disqus